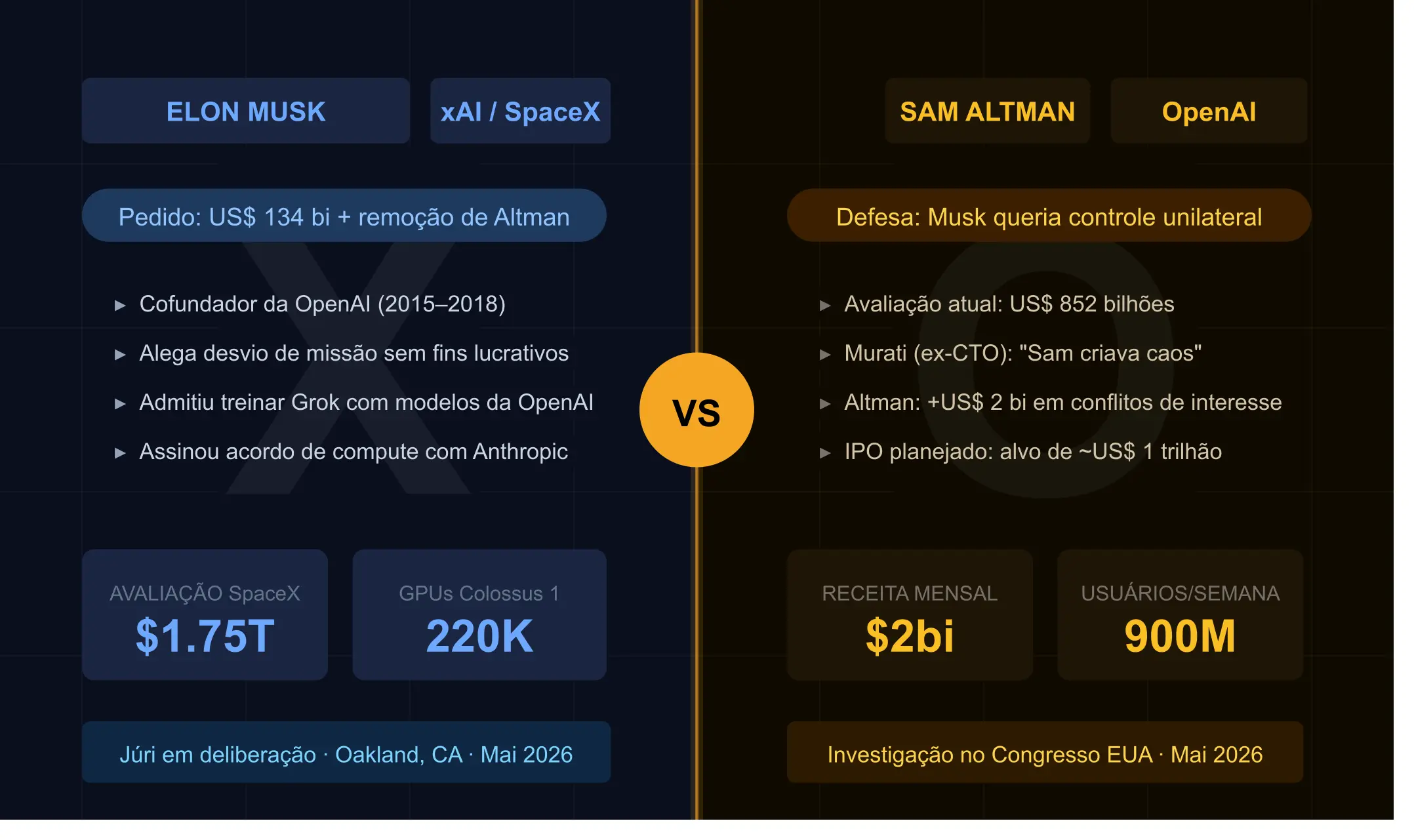
Nos últimos anos, os Modelos de Linguagem de Grande Escala (LLMs) se tornaram parte essencial de projetos de inovação, desde automação corporativa até suporte ao cliente e análise de dados. Entretanto, uma dúvida recorrente entre profissionais e empresas é: vale mais a pena rodar o modelo localmente ou consumir como serviço na nuvem (ex.: OpenAI, Anthropic, etc.)?
Diferenças Fundamentais
1. Infraestrutura e Custos
- Local (On-Premises): exige investimento em hardware de alto desempenho (GPUs, storage, rede), além de equipe especializada para operação. O custo inicial (CAPEX) é elevado, mas pode ser vantajoso em cenários de uso intensivo e previsível.
- Serviço (Cloud): segue o modelo pay-as-you-go, com custos variáveis conforme volume de requisições. Elimina o investimento inicial e reduz a necessidade de gestão de infraestrutura.
2. Desempenho e Latência
- Local: pode oferecer latência mínima, especialmente em redes internas, mas limitado à capacidade das GPUs disponíveis.
- Serviço: normalmente estável e otimizado, com a contrapartida da latência de rede.
3. Privacidade e Conformidade (LGPD, HIPAA, GDPR)
- Local: total controle sobre dados e logs. Essencial para setores regulados (saúde, financeiro, governo).
- Serviço: provedores oferecem cláusulas contratuais e anonimização, mas os dados sempre saem do perímetro da empresa.
4. Customização e Controle
- Local: máxima liberdade para treinar, ajustar e integrar o modelo a fluxos proprietários.
- Serviço: permite fine-tuning e ferramentas adicionais (function calling, embeddings, auditoria), mas dentro das restrições do provedor.
5. Escalabilidade e Atualizações
- Local: depende da capacidade instalada. Escalar exige compra de novos recursos.
- Serviço: escalabilidade elástica e atualizações automáticas, garantindo acesso a modelos de última geração.
Quando Usar Cada Abordagem
LLM Local (On-Premises)
- Projetos que exigem residência de dados ou operação offline.
- Ambientes com grande volume previsível de uso.
- Necessidade de controle fino do modelo (pesquisa, segurança, tuning profundo).
LLM como Serviço (Cloud)
- Provas de conceito e projetos em rápida evolução.
- Empresas que precisam de time-to-market rápido e não querem gerir infraestrutura.
- Cenários de carga variável ou imprevisível.
O Caminho Híbrido
Na prática, muitas empresas têm adotado soluções híbridas:
- RAG (Retrieval-Augmented Generation) local + modelo em nuvem, garantindo que dados sensíveis nunca saiam do ambiente corporativo.
- Roteamento inteligente, onde consultas críticas rodam localmente e tarefas criativas são direcionadas para serviços na nuvem.
- Fallback arquitetural, mantendo resiliência em caso de indisponibilidade do serviço.
Conclusão
A escolha entre rodar um LLM local ou consumir como serviço depende de três fatores principais: dados, custo e prazo.
- Se segurança e residência de dados são prioritárias, o caminho local é o mais indicado.
- Se a meta é velocidade, escala e acesso a modelos de ponta, a nuvem se destaca.
- Em muitos casos, o modelo híbrido entrega o melhor dos dois mundos.
O ponto central é alinhar a estratégia de IA ao contexto regulatório, à maturidade tecnológica da organização e aos objetivos de negócio.